1. OmniSciDB at 30,000 Feet¶
OmniSciDB is made up of several high level components. A diagram illustrating most of the components of the system is displayed below, with a short description of each major section of the documentation following.
1.1. High Level Diagram¶
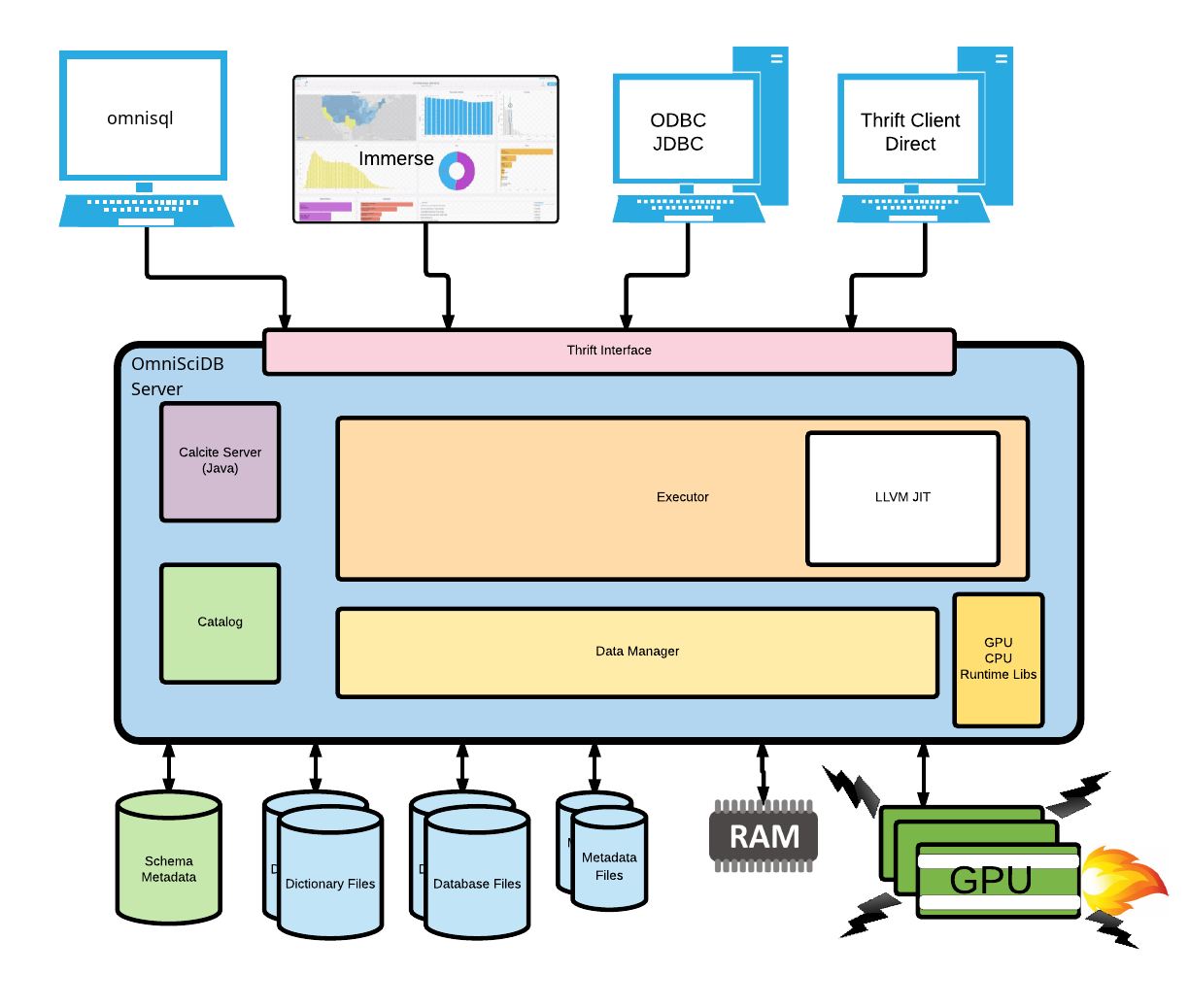
The major components in the above diagram and their respective reference pages are listed in the table below.
Component |
Reference Page |
|---|---|
Thrift Interface |
|
Calcite Server |
|
Catalog |
|
Executor |
|
LLVM JIT |
|
CPU / GPU Kernels |
|
Database Files, Metadata Files, Dictionary Files |
1.2. Data Model¶
The Data Model section provides an overview of the data formats and data types supported by OmniSciDB. A brief overview of various storage layer components is also included.
1.3. Data Flow¶
The Data Flow section ties together the Data Model and Query Execution sections, providing information about the complete flow of data from the input columns for a query to its projected outputs.
1.4. Query Execution¶
The Query Execution section provides an overview of how a query is executed inside OmniSciDB.
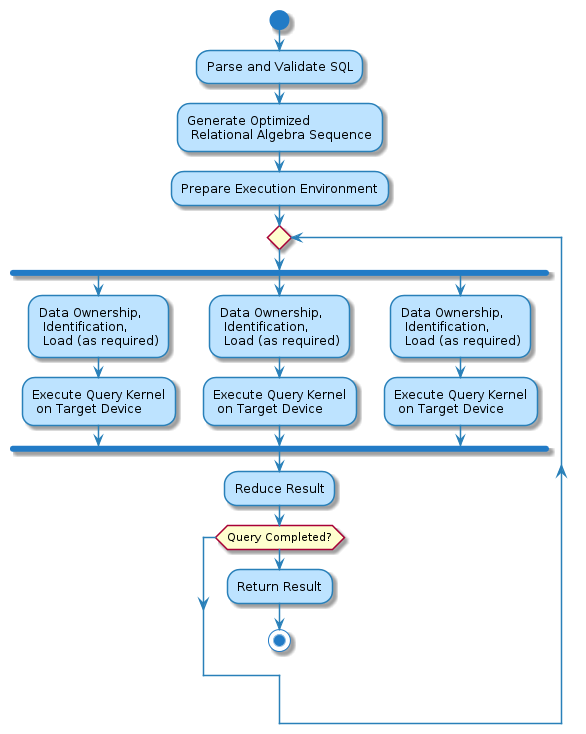
At a high-level, all SQL queries made to the server pass through the Thrift sql_execute endpoint. The query string is passed to Apache Calcite for parsing and cost-based optimization, yielding an optimized relational algebra tree. This relational algebra tree is then passed through OmniSci-specific optimization passes and translated into an OmniSCi-specific abstract syntax tree (AST). The AST provides all the information necessary to generate native machine code for query execution on the target device. Execution then occurs in parallel on the target device, with device results being aggregated and reduced into a final ResultSet for each query step.
The sections following provide in-depth details on each of the stages involved in executing a query.
1.5. Simplified Execution Model¶