6. Calcite Parser¶
OmniSciDB offloads query string parsing and cost-based optimization of the input SQL query to Apache Calcite. Calcite generates extended relational algebra from SQL queries, returning a relational algebra tree serialized inside a JSON string.
One of the main strengths of Calcite is its highly modular structure, which allows for multiple integration points and creative uses. It offers a relational algebra builder, which makes moving to a different SQL parser (or adding a non-SQL frontend) feasible. In OmniSciDB, additional runtime functions which are not recognized by Calcite by default are necessary. For example, trigonometric functions are required for on-the-fly geospatial projections. Fortunately, Calcite allows specifying such functions and they become first-class citizens, with proper type checking in place.
Calcite also includes a highly capable and flexible cost-based optimizer, which can apply high-level transformations to the relational algebra based on query patterns and statistics. For example, it can push part of a filter through a join in order to reduce the size of the input, like the following figure shows:
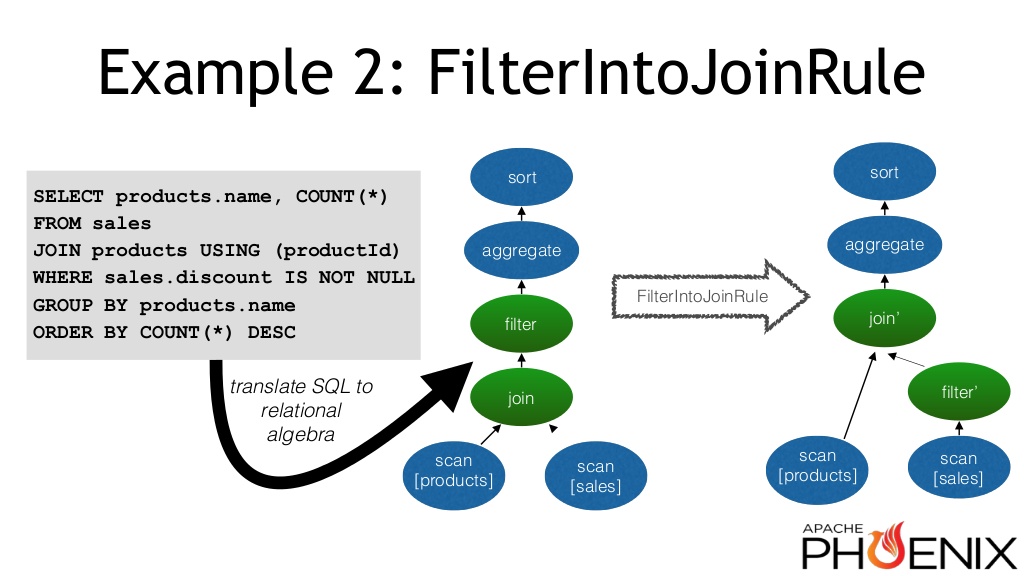
More information about Calcite’s cost-based optimizer is available in this presentation on using it in the Apache Phoenix project. Such optimizations complement the low-level optimizations in OmniSciDB (e.g. operator fusion) to achieve great speed improvements.
Let’s take a simple query:
SELECT A.x, COUNT(*) FROM test JOIN B ON A.x = B.x WHERE A.y > 41 GROUP BY A.x;
and analyze the relational algebra generated for it.
In Calcite relational algebra, there are a few main node types, corresponding to the theoretical extended relational algebra model: Scan, Filter, Project, Aggregate and Join. Each type of node, except Scan, has one or more (in the case of Join) inputs and its output can become the input of another node. The graph of nodes connected by data flow relationships is a directed acyclic graph (abbreviated as “DAG”). For our query, Calcite outputs the following DAG:
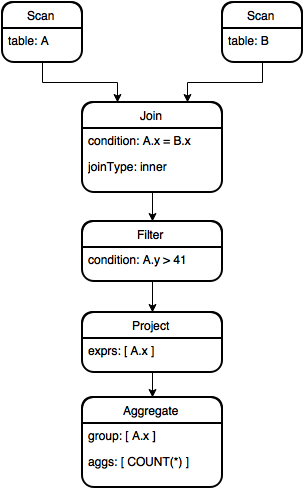
The Scan nodes have no inputs and output all the rows and the columns in tables A and B, respectively. The Join node specifies the join condition (in our case A.x = B.x) and its output contains the columns in A and B concatenated. The Filter node only allows the rows which pass the specified condition and its output preserves all columns of input. The Project node only preserves the specified expressions as columns in the output. Finally, the Aggregate specifies the group by expressions and aggregates.
The physical implementation of the nodes is up to the system using Calcite as a frontend. Nothing in the Join node mandates a certain implementation of the join operation (equijoin in OmniSciDB). Indeed, using a condition which can’t be implemented as a hash join, like A.x < B.x, would only be reflected by the condition in the Filter node.
6.1. Communication between Calcite and OmniSciDB¶
Calcite requires information about the current table schema in order to build the RA tree. Specifically, the table names, column names, and column types for each table must all be shared with Calcite. Once the query string has been parsed, Calcite dynamically queries the OmniSciDB server for table and column metadata for each table and each column involved in the query. To make this query, Calcite requires an authenticated session. A special Calcite-only session is established at server startup for Calcite to make reverse requests back to the server. This session can read all table metadata, but cannot make modifications.
For unit test purposes, OmniSciDB runs in headless mode. In the headless mode environment, there is no OmniSciDB server for Calcite to query. Instead, Calcite directly accesses SQLite metadata for each database. A separate serialization interface exists for temporary tables, which are not persisted to SQLite. Temporary tables are serialized in JSON format to a separate file and loaded by Calcite for each query.