7.5. Execution Kernels¶
Each query step is executed in parallel. The smallest unit of parallelism in OmniSciDB is a fragment. The QueryFragmentDescriptor determines fragments required for computation and assigns them to an ExecutionKernel, which is then launched asynchronously using a thread pool. Once execution is finished, device results are stored in a ResultSet. After all devices have finished, the ResultSet objects are reduced to a single ResultSet which is returned to the caller.
Each device (GPU or CPU thread) has a dedicated CPU thread. All devices initialize state and execute queries in parallel. On CPU, this means the execution within a single device is not parallel. On GPU, execution within a device also occurs in parallel.
Input data is assigned to the relevant device in a pre-processing step. Input fragments are typically assigned in round-robin order, unless the input data is sharded. For sharded input data, all shards of the same key are assigned to the same device. Input assignment is managed by the QueryFragmentDescriptor.
The execution process consists of the following main steps (each run concurrently per execution device):
Fetch all assigned input chunks (assigned input fragments across columns required for the query).
Prepare output buffers (allocation and initialization if necessary).
Execute the generated code (i.e. launch kernels on the device).
Prepare
ResultSetand return (reducing if necessary).
Per-kernel execution is managed by the ExecutionKernel class with shared state residing in SharedKernelContext. Each execution kernel manages the execution process on a single device (either a CPU thread or an entire GPU). Each kernel creates a QueryExecutionContext, which owns and manages the state for the duration of the kernel execution on the device.
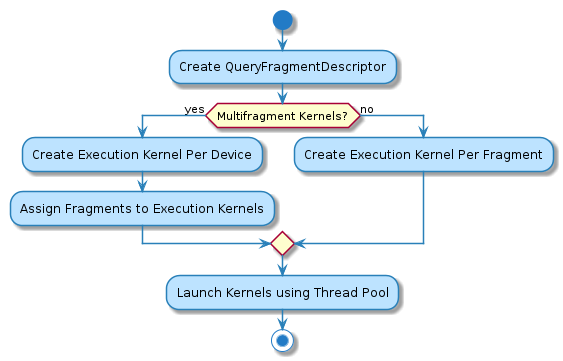
7.5.1. Query Fragment Descriptor¶
The basic unit of work in OmniSciDB is a fragment. The QueryFragmentDescriptor class maintains useful information about fragments that are involved with execution of a particular work unit; most importantly, the fragment descriptor partitions fragments among all available devices based on the execution mode (described below).
7.5.1.1. Execution Modes:¶
Kernel Per Fragment: Each outer table fragment in the query executes using its own kernel. This mode is used for CPU execution, on GPU when lazy fetch is enabled, and for
SELECT * LIMIT Nqueries without a filter (where the executor can terminate early without a full table scan by tracking the number of tuples seen and quitting afterN).Multi-fragment Kernels: Outer table fragments are assigned across a number of kernels equal to the number of available execution devices. Currently, multi-fragment kernels are only used on GPU. Because the GPU parallelizes within a kernel, multi-fragment kernels are more efficient, as they run in parallel across all fragments and require fewer GPU kernel launches.
7.5.2. Execution Kernel¶
As discussed above, the QueryFragmentDescriptor assigns fragments to devices (i.e., kernels). Using this information, the Executor creates an ExecutionKernel per fragment (or fragment group in a multi-fragment kernel) and then launches all kernels asynchronously using a thread pool. The individual ExecutionKernel takes as input compiled code and a fragments list, and manages data fetching, launching native code, and bringing results back from GPU (if required). A set of ExecutionKernel objects for a given query share state, and will place their results in the SharedKernelContext once execution has completed and any results have been retrieved from an execution device (e.g. GPU).
7.5.3. Query Execution Context¶
The QueryExecutionContext object is created for each device and manages the following high level tasks:
Prepares for kernel execution (setup output buffers, parameters, etc)
Launches the execution kernel on the device
Handles errors returned by the kernel (if any)
Transfers the output buffers from the device back to the host (for GPU execution)
While the same execution context is created for CPU and GPU execution, the exact procedure for each mode is slightly different.
7.5.3.1. CPU execution¶
![@startuml
(*) --> "Initialization"
--> "CPU Output Buffer Allocation / Initialization"
if "is Group By / Projection" then
-->[true] "Execute Plan With Group By"
--> "Launch CPU Code"
else
-> [false] "Execute Plan Without Group By"
--> "Launch CPU Code"
endif
--> "Reduce inter-device Results"
-right-> (*)
@enduml](../_images/plantuml-d3a5691dae6716e43f6eb86d8e334ce936088c1b.png)
7.5.3.2. GPU execution¶
![@startuml
(*) --> "Initialization"
--> "CPU Output Buffer Allocation / Initialization"
--> "GPU Output Buffer Allocation / Initialization"
if "is Group By / Projection" then
-->[true] "Execute Plan With Group By"
--> "Launch GPU Code"
else
-> [false] "Execute Plan Without Group By"
--> "Launch GPU Code"
endif
--> "Prepare Kernel Params"
--> "Launch Cuda Kernel"
--> "Copy Back Output Buffer"
--> "Reduce inter-device Results"
-right-> (*)
@enduml](../_images/plantuml-9f6e192b7ea2f24f08f1162fc609039d88c6a30c.png)
Note
Some queries will allocate more than one output buffer on the GPU to reduce thread contention during parallel intra-fragment execution. For each allocated output buffer on the GPU, a match output buffer on CPU is also allocated to support copying results back from the GPU once execution finishes.
All arguments for the GPU kernel must be allocated in GPU memory and copied to the device. The GPU kernel launch function takes a pointer to the GPU generated code (in device memory) and a pointer to the kernel parameters buffer (also in device memory).
Kernel launches on GPU are asynchronous; that is, cuLaunchKernel returns immediately after the kernel successfully starts on the device. The next call to the nVidia CUDA driver API is blocking. Immediately after the kernel is launched, an attempt is made to copy the error codes buffer back using the CUDA driver API. This call is blocking; therefore, if the kernel generates an error during execution, we will detect it only after the entire kernel finishes.