4.1. Columnar Data Organization¶
4.1.1. Columns¶
OmniSciDB is a columnar database. Columns in OmniSciDB are organized into fragments (striping across rows) and chunks (the intersection of a column and a fragment). The following sections describe fragment and chunk organization and layout in depth.
4.1.2. Fragments¶
A fragment describes a horizontal partition of a set of rows in a table. A set of fragments makes up a table (see Diagram below). By default, each fragment will consist of 32 million records. Fragment size is configurable when the table is created (see CREATE TABLE).
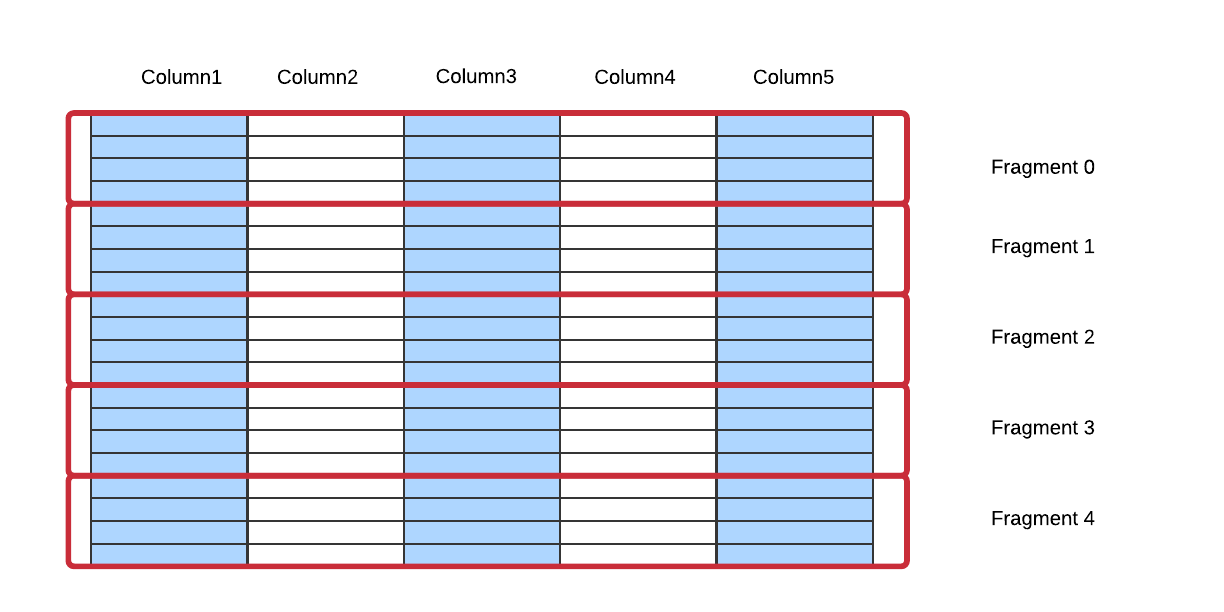
4.1.3. Chunks¶
A chunk represents a vertical partition of a fragment. The set of chunks corresponding to the same set of rows across all columns in a given table makes up a single fragment. A chunk is the smallest unit of device-level data parallelism in OmniSciDB. Therefore, an important part of optimizing schema is picking the appropriate chunk width and fragment size. Different chunks in a given fragment will contain the same number of items, but depending on the data type of the column the size of the chunks (in bytes) will differ. By default, a chunk has a maximum size of 1 GB.
Once loaded into memory, the in-memory Chunk representation contains both the raw data for the chunk and additional metadata (ChunkStats). The additional metadata is used to optimize query execution. For example, ChunkStats allows OmniSciDB to only load chunks directly relevant to the query; e.g. SELECT x FROM t WHERE x > 10 would rely on ChunkStats to ensure all chunks with max less than or equal to 10 are skipped.
ChunkStats are updated every time a table update or delete occurs, or whenever new data is inserted into the chunk. Note that ChunkStats are only ever widened. The OPTIMIZE command can be used to narrow chunk stats (e.g. after multiple deletes have occured for a given table).
struct ChunkStats {
Datum min;
Datum max;
bool has_nulls;
};
struct ChunkMetadata {
SQLTypeInfo sqlType;
size_t nuMB;
size_t numElements;
ChunkStats chunkStats;
}
4.1.3.1. Example for chunk physical representations¶
The example is based on a table t, defined using the below DDL, with the default fragment size of 32 million rows and default chunk size of 1 GB, loaded with 8 million (8M) records.
create table t(
c1 SMALLINT,
c2 INTEGER
)
The table will consist of a single fragment with the following two chunks;
chunk payload for c1 will be 8M x 2 bytes (SMALLINT size) = 16MB in actual chunk physical size
chunk payload for c2 will be 8M x 4 bytes (INT size) = 32MB in actual chunk physical size.
Now consider loading t with 40M rows. Now, t consists of two fragments. The first fragment contains the following two chunks:
chunk payload for c1 will be 32M x 2 bytes (SMALLINT size) = 64MB in actual chunk physical size
chunk payload for c2 will be 32M x 4 bytes (INT size) = 128MB in actual chunk physical size.
The second fragment contains the remaining 8M records:
chunk payload for c1 will be 8M x 2 bytes (SMALLINT size) = 16MB in actual chunk physical size
chunk payload for c2 will be 8M x 4 bytes (INT size) = 32MB in actual chunk physical size.
During import, the Fragmenter handles assigning input data to a fragment and creating new fragments once the current fragment is full.
4.1.3.2. ChunkKey¶
The ChunkKey is a set of integer values that uniquely identify a chunk. The ChunkKey is represented using a C++ vector with 4 to 5 entries, depending on the data type of the chunk. Roughly, the entries correspond to DB, Table, Column, Fragment, and IsVarlenOffsetSubChunk. Note that a negative DB identifier refers to an ephemeral chunk, created during an intermediate query execution step as a temporary result for input to the next step.
The table below describes the ChunkKey representation for common chunk indexing scenarios across the system.
ChunkKey[0] |
ChunkKey[1] |
ChunkKey[2] |
ChunkKey[3] |
ChunkKey[4] |
Description |
|---|---|---|---|---|---|
-1 |
idx < 0 |
idx > 0 |
idx == 0 |
Ephemeral temp chunk (only one fragment currently supported) |
|
db > 0 |
tb > 0 |
col > 0 |
frag >= 0 |
References a scalar chunk from OmniSciDB storage |
|
db > 0 |
tb > 0 |
col > 0 |
frag >= 0 |
var > 0 |
References a unique varlen chunk from OmniSciDB storage. Var indicates whether the chunk is a data chunk or an index (offset) chunk |